Using artificial intelligence to train teams of robots to work together
(Nanowerk News) When communication lines are open, individual agents such as robots or drones can work together to collaborate and complete a task. But what if they aren’t equipped with the right hardware or the signals are blocked, making communication impossible? University of Illinois Urbana-Champaign researchers started with this more difficult challenge. They developed a method to train multiple agents to work together using multi-agent reinforcement learning, a type of artificial intelligence (Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, "Disentangling Successor Features for Coordination in Multi-agent Reinforcement Learning"; PDF).
“It’s easier when agents can talk to each other,” said Huy Tran, an aerospace engineer at Illinois. “But we wanted to do this in a way that's decentralized, meaning that they don't talk to each other. We also focused on situations where it's not obvious what the different roles or jobs for the agents should be.”
Tran said this scenario is much more complex and a harder problem because it’s not clear what one agent should do versus another agent.
“The interesting question is how do we learn to accomplish a task together over time,” Tran said.
Tran and his collaborators used machine learning to solve this problem by creating a utility function that tells the agent when it is doing something useful or good for the team.
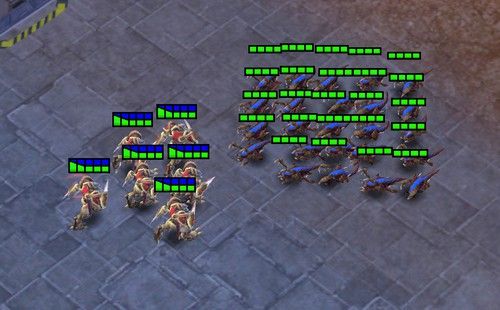
Aerospace engineer Huy Tran and his colleagues tested their algorithms using simulated games like StarCraft, a popular computer game. (Image courtesy of the researchers)
“With team goals, it's hard to know who contributed to the win,” he said. “We developed a machine learning technique that allows us to identify when an individual agent contributes to the global team objective. If you look at it in terms of sports, one soccer player may score, but we also want to know about actions by other teammates that led to the goal, like assists. It’s hard to understand these delayed effects.”
The algorithms the researchers developed can also identify when an agent or robot is doing something that doesn’t contribute to the goal. “It’s not so much the robot chose to do something wrong, just something that isn’t useful to the end goal.”
They tested their algorithms using simulated games like Capture the Flag and StarCraft, a popular computer game.
You can watch a video of Huy Tran demonstrating related research using deep reinforcement learning to help robots evaluate their next move in Capture the Flag.
“StarCraft can be a little bit more unpredictable – we were excited to see our method work well in this environment too.”
Tran said this type of algorithm is applicable to many real-life situations, such as military surveillance, robots working together in a warehouse, traffic signal control, autonomous vehicles coordinating deliveries, or controlling an electric power grid.
Tran said Seung Hyun Kim did most of the theory behind the idea when he was an undergraduate student studying mechanical engineering, with Neale Van Stralen, an aerospace student, helping with the implementation. Tran and Girish Chowdhary advised both students. The work was recently presented to the AI community at the Autonomous Agents and Multi-Agent Systems peer-reviewed conference.