Systems Biology: Network Modeling, Multi-Omics Integration, and Computational Approaches
What Is Systems Biology?
Systems biology is an interdisciplinary field that studies biological systems by integrating experimental data with computational and mathematical modeling to understand how molecular components interact to produce the behaviors of cells, tissues, and organisms. Rather than examining individual genes, proteins, or metabolites in isolation, systems biology treats the cell as an interconnected network whose properties emerge from the collective dynamics of its parts. This integrative perspective distinguishes the field from classical molecular biology, which traditionally focuses on one pathway or molecule at a time.
The formal foundations of systems biology were articulated in the early 2000s, when Leroy Hood and colleagues at the Institute for Systems Biology in Seattle proposed a framework combining systematic perturbation of biological systems with high-throughput measurement of genome-wide responses and mathematical modeling. Hiroaki Kitano outlined the field's core challenge in a 2002 Science article: understanding the structure and dynamics of cellular function at the system level, where properties such as robustness emerge that cannot be predicted from the characteristics of isolated parts.
Systems biology today spans scales from single molecules to whole organisms and even ecosystems. Its methods draw on genomics, transcriptomics, proteomics, and metabolomics to generate comprehensive molecular inventories, and on bioinformatics and mathematical modeling to integrate these datasets into predictive frameworks. The iterative cycle of model building, experimental testing, and model refinement—in which failed predictions are as informative as successful ones—is the defining workflow of the discipline.
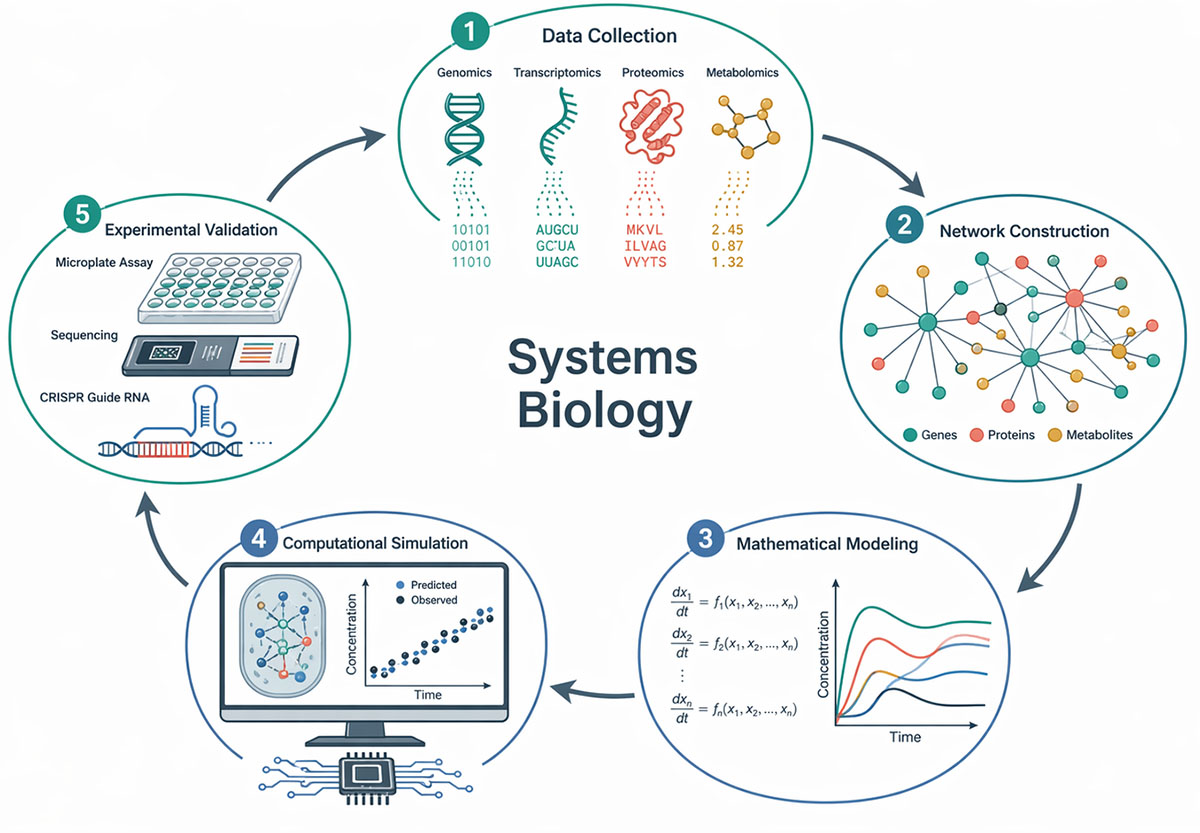
How Systems Biology Works: Networks, Models, and Simulations
At the conceptual core of systems biology lies the biological network. Cells operate through interconnected webs of molecular interactions: protein–protein interaction networks map physical associations between proteins; transcriptional regulatory networks describe how transcription factors control gene expression; metabolic networks trace the flow of small molecules through enzyme-catalyzed reactions; and signaling networks relay information from cell-surface receptors to downstream effectors. Each of these network types can be represented mathematically as a graph, with molecules as nodes and interactions as edges.
Network analysis revealed that biological networks share structural properties with other complex systems. Cellular networks are scale-free: a small number of highly connected hub nodes hold the network together, while most nodes have few connections. This architecture confers robustness against random perturbations—removing a low-connectivity node rarely disrupts the network—but creates vulnerability to targeted attacks on hubs, a finding with direct implications for understanding both genetic diseases and drug target selection.
The identification of recurring circuit patterns called network motifs, such as feed-forward loops and autoregulatory circuits, showed that biological networks are not wired randomly but contain functional modules that carry out specific information-processing tasks. These motifs appear across organisms from bacteria to humans, suggesting that evolution converges on the same regulatory logic when a particular computation—such as filtering noise or generating pulses—is needed.
Mathematical models translate network topology into quantitative predictions. Ordinary differential equation (ODE) models describe how the concentrations of molecular species change over time based on their rates of production, degradation, and interaction. These models have been used extensively to study signaling cascades, circadian clocks, and cell cycle regulation. For genome-scale metabolic networks, constraint-based approaches such as flux balance analysis (FBA) predict the flow of metabolites through thousands of reactions simultaneously, using stoichiometric constraints and optimization principles rather than detailed kinetic parameters.
Stochastic models account for the inherent randomness of biochemical reactions in individual cells, where low molecule numbers can produce significant cell-to-cell variability even in genetically identical populations. Boolean network models, which represent each gene as either on or off, capture the logic of regulatory circuits without requiring precise kinetic measurements. Agent-based models simulate the behavior of individual cells within tissues, linking intracellular molecular networks to tissue-level phenomena such as tumor growth or immune responses.
Core Technologies Used
Systems biology depends on high-throughput technologies that can simultaneously measure thousands of molecular species. DNA sequencing provides the parts list: the complete set of genes encoded in an organism's DNA. RNA sequencing reveals which genes are actively transcribed under a given condition. Mass spectrometry-based proteomics quantifies thousands of proteins, while metabolomics platforms profile small-molecule metabolites. Single-cell versions of these assays now resolve molecular heterogeneity within cell populations that bulk measurements obscure.
Multi-omics integration—the simultaneous analysis of data from two or more omics layers—is central to the systems biology approach. By combining, for example, transcriptomic and proteomic profiles from the same samples, researchers can identify post-transcriptional regulatory mechanisms that are invisible to either technique alone. Statistical methods such as weighted gene co-expression network analysis (WGCNA), canonical correlation analysis, and more recently deep learning approaches are used to extract biologically meaningful patterns from these high-dimensional datasets.
Perturbation experiments complement observational omics by providing causal information. Systematic gene knockouts, RNA interference screens, and CRISPR-Cas9-based genetic screens allow researchers to observe how the system responds when individual components are removed or altered. Combining these perturbations with multi-omics readouts distinguishes true regulatory relationships from mere correlations—a critical step in building network models that accurately predict the consequences of interventions.
Applications in Research and Medicine
Cancer research has been one of the most productive application areas for systems biology. Tumor cells accumulate mutations across multiple signaling pathways, and understanding how these alterations interact to drive malignancy requires a network-level perspective. Genome-scale models of cancer metabolism have identified metabolic vulnerabilities specific to tumor cells, revealing potential drug targets that would not be apparent from studying individual enzymes. Network-based analyses of patient omics data are used to stratify tumors into molecular subtypes, predict treatment response, and identify biomarkers for personalized medicine.
Drug discovery benefits from systems biology through the identification of drug targets in the context of the full network, rather than in isolation. Network pharmacology—an approach that maps drug–target–disease relationships across the interactome—has helped explain why some drugs are effective against diseases beyond their original indication and why others produce unexpected side effects. Multi-target drug design strategies, informed by network analysis, aim to modulate disease networks at multiple points simultaneously, which can improve therapeutic efficacy while reducing the likelihood of resistance.
Microbial systems biology has enabled the rational engineering of microorganisms for industrial biotechnology. Genome-scale metabolic models of Escherichia coli, Saccharomyces cerevisiae, and other workhorses of synthetic biology guide the design of metabolic pathways for producing biofuels, pharmaceuticals, and specialty chemicals. These models predict which genes to overexpress, delete, or regulate to redirect metabolic flux toward a desired product, substantially reducing the trial-and-error of traditional strain engineering.
In 2012, a landmark in the field was the publication of the first whole-cell computational model, which described the complete life cycle of the bacterium Mycoplasma genitalium. The model integrated 28 submodels covering metabolism, transcription, translation, DNA replication, and cell division, accounting for the functions of 401 genes and over 1,800 reactions. This work demonstrated that it is feasible, at least for a simple organism, to simulate cellular behavior from the molecular level up.
Integration with Other Omics Disciplines
No single omics layer is sufficient to explain complex phenotypes such as drug resistance, cellular differentiation, or disease progression. Systems biology serves as the integrative framework that connects genomics, transcriptomics, proteomics, metabolomics, and epigenomics into a coherent picture. The principal challenge lies in the heterogeneity of these data: different omics platforms produce measurements at different scales, with different noise profiles, missing-data patterns, and temporal resolutions. Reconciling these disparities requires both computational methods and biological scaffolds onto which the data can be anchored.
Genome-scale network models provide a natural scaffold for this integration. Metabolic reactions link genes to enzymes to metabolites, and regulatory networks link transcription factors to their target genes. By mapping omics measurements onto these network structures, researchers can contextualize individual data points within known biological pathways and infer system-level properties such as pathway activity, metabolic flux distributions, and regulatory bottlenecks that no single data type reveals on its own.
Spatial omics technologies are adding a further dimension to multi-omics integration. Spatially resolved transcriptomics and proteomics preserve tissue architecture while profiling molecular composition, enabling systems-level analyses that account for the physical organization of cells within tissues. Combining spatial data with single-cell multi-omics is beginning to connect intracellular molecular states to tissue-scale function in ways that dissociated-cell approaches cannot achieve, opening new avenues for understanding development, disease microenvironments, and organ physiology.
Future Directions
Whole-cell modeling remains a central aspiration of the field. Building on the Mycoplasma genitalium precedent, several groups are developing whole-cell models of more complex organisms, including E. coli and human cell types. The concept of the biological digital twin—a personalized computational model of an individual patient's molecular network—is gaining traction in precision medicine, where it could be used to simulate drug responses and predict disease trajectories before treatment decisions are made.
Artificial intelligence is reshaping the computational landscape of systems biology. Graph neural networks can infer regulatory relationships directly from expression data, bypassing the need for manually curated pathway databases. Large-scale foundation models trained on biological sequences and structures are beginning to predict protein function, interaction partners, and the effects of genetic variants at unprecedented scale. The integration of these AI-driven approaches with mechanistic models—a hybrid strategy that combines the interpretability of physics-based models with the predictive power of data-driven methods—represents a particularly active frontier.
As datasets grow in size and complexity, the reproducibility and standardization of systems biology models have become critical concerns. Community-driven initiatives to curate and share models in standardized formats, benchmark model performance against common datasets, and develop uncertainty quantification methods are strengthening the reliability of computational predictions. These efforts are essential if systems biology is to fulfill its potential as a predictive science capable of guiding experimental design, clinical decisions, and the engineering of biological systems.
Frequently Asked Questions
How does systems biology differ from traditional molecular biology? Traditional molecular biology typically studies individual genes, proteins, or pathways in isolation, seeking to understand one component at a time. Systems biology, by contrast, treats the cell or organism as an integrated network and asks how components interact to produce system-level behaviors such as robustness, oscillation, or bistability. This shift requires computational modeling, high-throughput data collection, and mathematical frameworks that are not part of the classical molecular biology toolkit.
What programming languages and tools are commonly used in systems biology? Python and R are the most widely used programming languages, supported by libraries such as COBRApy for constraint-based metabolic modeling, PySB for rule-based modeling of signaling networks, and Bioconductor packages for omics data analysis. MATLAB remains common in dynamical systems modeling. Standardized formats such as SBML (Systems Biology Markup Language) allow models to be shared and reproduced across different simulation platforms, including COPASI, CellDesigner, and Virtual Cell.
Can systems biology be applied to non-model organisms? Yes, although the depth of modeling depends on available data. Advances in high-throughput sequencing and mass spectrometry have made it possible to generate genome-scale datasets for virtually any organism. Constraint-based metabolic models, for example, have been reconstructed for hundreds of species, including industrially relevant microbes, crop plants, and marine organisms. The main limitation is the quality of genome annotation and the availability of experimentally validated biochemical parameters for the organism of interest.
What is a digital twin in the context of systems biology? A digital twin is a computational replica of a biological system—such as a single cell, a tissue, or an individual patient—that can be used to simulate responses to perturbations, predict disease progression, or test therapeutic interventions in silico before applying them in the laboratory or clinic. The concept borrows from engineering, where digital twins of aircraft engines and industrial processes are well established. In biology, whole-cell models and patient-specific metabolic models represent early steps toward this goal.
How is artificial intelligence changing systems biology? Machine learning and deep learning are accelerating several areas of systems biology. Graph neural networks can predict gene–gene interactions and infer regulatory relationships from expression data. Generative models can propose novel metabolic pathway designs for synthetic biology. Large language models trained on biomedical literature help extract structured knowledge for building and annotating biological networks. AI is also improving the integration of multi-omics datasets by learning non-linear relationships across molecular layers that traditional statistical methods struggle to capture.
Further Reading
Science, Systems Biology: A Brief Overview
Annual Review of Genomics and Human Genetics, A New Approach to Decoding Life: Systems Biology
Nature Reviews Genetics, Network Biology: Understanding the Cell's Functional Organization
Annual Review of Biomedical Engineering, The Evolution of Systems Biology and Systems Medicine: From Mechanistic Models to Uncertainty Quantification
