| Posted: Nov 30, 2015 |
Using 'big data' to shed light on the complexity of nanomaterials |
| (Nanowerk Spotlight) For decades computational physicists, chemists and nanoscientists have been assuming the lowest energy structures are the most representative. Since very few physical systems are ever in the ground state, this assumption biases the results towards an idealized minority. |
| Using multivariate data analytics scientists can, for the first time, identify the truly quintessential nanostructures, that actually are representative. |
| "Using these structures – which are rarely the low energy ones – we can bias predictions toward the majority of the sample, and obtain better agreement with experiment," Dr. Amanda S. Barnard, who leads the CSIRO Virtual Nanoscience Laboratory, tells Nanowerk. |
| Together with Dr Michael Fernandez, Barnard has presented a methodology to identify nanoparticles with unique combinations of features and, in general, a feasible way of in silico characterization of intractable nanomaterial spaces. The findings have been published in the November 17, 2015 online edition of ACS Nano ("Identification of Nanoparticle Prototypes and Archetypes"). |
 |
| Not all nanoparticles are created equal. Identifying the archetypes and prototypes from among the myriad of possibilities is the first step in reducing the complexity of real, polydispersed ensembles. (Image: Dr. Barnard, CSIRO) |
| "To the best of our knowledge this is the first statistical characterization of nanostructure ensembles and the identification of their representative members," the two scientists point out. "This is a demonstration of one of the many ways that data science can impact the study of complex nanoscale materials. It is not enough to have big data, we have to make sure it is useful. Unless we can clearly identify which data points (nanostructures) are actually important, big data will provide us with nothing but noise." |
| Ever since research and manufacture of nanomaterials has moved into the mainstream, scientists have grappled with a considerable characterization challenge. Health and environmental considerations, for instance, need to deal with the complexities that affect the biological interactions of the nanomaterial; or take the nanoelectronics and nanosensor areas, where even minute changes in a nanoscale material or structure could massively change their performance. |
| The enormous complexity arises from the sheer vastness of potential combinatorial variations that can be developed by choosing different nanomaterial size (including agglomeration and aggregation), solubility/dispersibility, chemical form, chemical reactivity, surface chemistry, shape, and porosity. |
| "The number of possible materials is increasing exponentially, along with their intrinsic structural complexity, making even the application of efficient density functional theory infeasible," says Barnard. "Nanomaterials are more complicated, because their properties are intrinsically linked to their size, shape, and types of surfaces. Unexpected variability in shape can have detrimental effects in the nanoparticle behavior and their functional properties. This represents a tremendous challenge because the selection of experimentally significant samples becomes increasingly difficult and requires knowledge of the relevant sizes, shapes, and structural complexity a priori." |
| The age of big data has arrived, and scientists are discovering more useful structure/property correlations all the time. Correlations show how structures and properties are related, but not why. |
| "To understand the mechanisms that underpin structure/property relationships we need to undertake detailed studies of a limited set of 'representative' nanostructures," Barnard points out. "With our approach, the truly representative and 'pure type' nanostructures can now be definitely identified, taking the guess work and assumption out of choosing the appropriate model systems for these types of studies." |
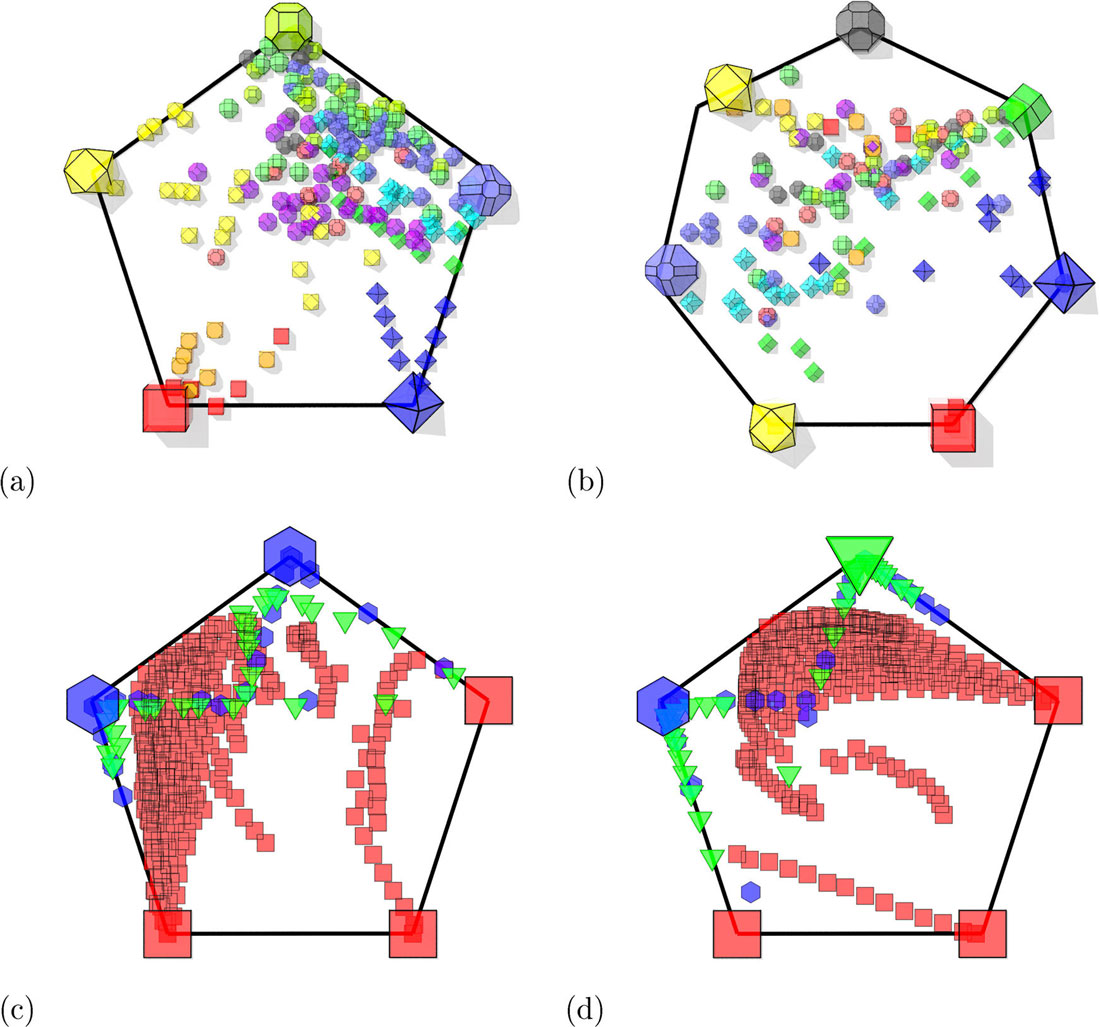 |
| Simplex plots of the (a) nanodiamonds, (b) bucky-diamonds, (c) passivated, and (d) unpassivated graphenes, where the archetypes are located toward the edges of the regular polygons, and the nanoparticles are scattered as projections of the archetypes in the simplex (see Supporting Information for details). The larger shapes represent the archetypal nanoparticles. (Reprinted with permission by American Chemical Society) (click on image to enlarge) |
| With the resulting data, detailed studies of structure/property relationships can be made based on the structures that accurately represent the complexity and diversity of real samples. Since any hypothetical nanostructure can be described by a linear combination of archetype and prototypes, researchers can easily incorporate polydispersivity and heterogeneity into structure/property predictions. These predictions will be one step closer to reality. |
| In their paper, Barnard and Fernandez apply multivariate statistical techniques to the study of nanocarbons, using virtual nanodiamonds ranging from 437 to 6107 carbon atoms and graphene nanoflakes ranging from 16 to 2176 carbon atoms. |
| "For the first time, we use k-means clustering, archetypal analysis (AA), and principal component analysis (PCA) to explore the diversity of 182 (pure) nanodiamonds, 117 buckydiamonds, 311 unpassivated (radical) graphene nanoflakes, and 311 structurally equivalent hydrogen passivated nanoflakes," Barnard explains their work. "These analyses are based on structural features characterizing geometry, interatomic distances, bond angle, surface-to-volume ratio, carbon-to-hydrogen ratio, and hybridization fraction; many of which can be preselected without undertaking expensive electronic structure simulations." |
| "As we have shown, these methods are a powerful way of finding the truly representative nanostructures, which can be used in linear combination," she adds. "One of the great advantages of using big data sets is that we can encode the predictions with distributions that accurately reproduce real world observations. Now we know we can identify prototypical and archetypal nanostructures, we plan to investigate how the selection process is impacted by different statistical distributions of the data." |
| However, no matter how effective and efficient synthesis and processing strategies are, samples of nanoparticles will always exhibit some persistent polydispersivity. It is simply not economically feasible to ensure that every particle is atomically identical. |
| "This means that polydispersivity must be included when we predict structure/property relationships, but this is extremely challenging for the computational community who need to reduce the sample to a subset of representative structures," cautions Barnard. "However, until now, there has been no way of knowing if we have been choosing the right ones." |
| Big data and the application of multivariate data analytics to the complex world of nanomaterials is a new direction in nanoscience and technology, paved with enormous opportunity. Although there exists as range of well-established and reliable statistical methods, there are conceptual barriers that are proving challenging to overcome. |
| As the two scientists conclude, "it will be hard for a community accustomed to systematically seeking 'one perfect result' to embrace the uncertainty and messiness that is characteristic of big data; harder still to accept that creating data is not the same as creating value from data. It may be some time before data-driven research is accepted as another branch of nanoscience, but it is worth the effort as there are certain problems that cannot be solved any other way." |
 By
Michael
Berger
– Michael is author of four books by the Royal Society of Chemistry:
Nano-Society: Pushing the Boundaries of Technology (2009),
Nanotechnology: The Future is Tiny (2016),
Nanoengineering: The Skills and Tools Making Technology Invisible (2019), and
Waste not! How Nanotechnologies Can Increase Efficiencies Throughout Society (2025)
Copyright ©
Nanowerk LLC
By
Michael
Berger
– Michael is author of four books by the Royal Society of Chemistry:
Nano-Society: Pushing the Boundaries of Technology (2009),
Nanotechnology: The Future is Tiny (2016),
Nanoengineering: The Skills and Tools Making Technology Invisible (2019), and
Waste not! How Nanotechnologies Can Increase Efficiencies Throughout Society (2025)
Copyright ©
Nanowerk LLC
|

Become a Spotlight guest author! Join our large and growing group of guest contributors. Have you just published a scientific paper or have other exciting developments to share with the nanotechnology community? Here is how to publish on nanowerk.com. |
