Directed Evolution: How It Works, Methods, and Applications
What Is Directed Evolution?
Directed evolution definition: Directed evolution is a laboratory method that engineers proteins, enzymes and other biomolecules by applying repeated cycles of genetic diversification followed by screening or selection for an improved property.
In simple terms, directed evolution is trial-and-error breeding for molecules: make many variants, test them, keep the best, and repeat.
Directed evolution is a strategy in protein engineering that imitates natural selection inside the laboratory to obtain molecules with useful new properties. Rather than designing a sequence from first principles, the experimenter starts from a gene encoding a parent molecule, introduces large numbers of mutations to create a diverse library of variants, and then uses a screen or a selection to keep only the variants that perform best. The winners become the parents for the next round, and the cycle is repeated until the desired performance is reached. The molecule is not designed residue by residue; it is improved by breeding and selection.
At a glance:
- What it changes: DNA sequence
- What it optimizes: protein, enzyme, antibody or nucleic-acid function
- What decides success: the screen or selection used to identify improved variants
- Best for: molecular functions that are hard to design rationally
- Main bottleneck: assay quality, throughput and library coverage
- Recognition: the 2018 Nobel Prize in Chemistry
The power of the approach comes from the fact that biological function is encoded in a sequence that can be copied, mutated and selected. By keeping each tested molecule linked to the gene that encodes it, a researcher can recover the DNA sequence behind a successful variant and search enormous numbers of sequence variants for rare improvements that no human would have predicted. This makes directed evolution particularly valuable for goals that resist rational design, such as making an enzyme stable in an industrial solvent or active on a substrate it never encounters in nature. Frances Arnold pioneered the directed evolution of enzymes from the early 1990s, and the field has since become a standard part of biotechnology.
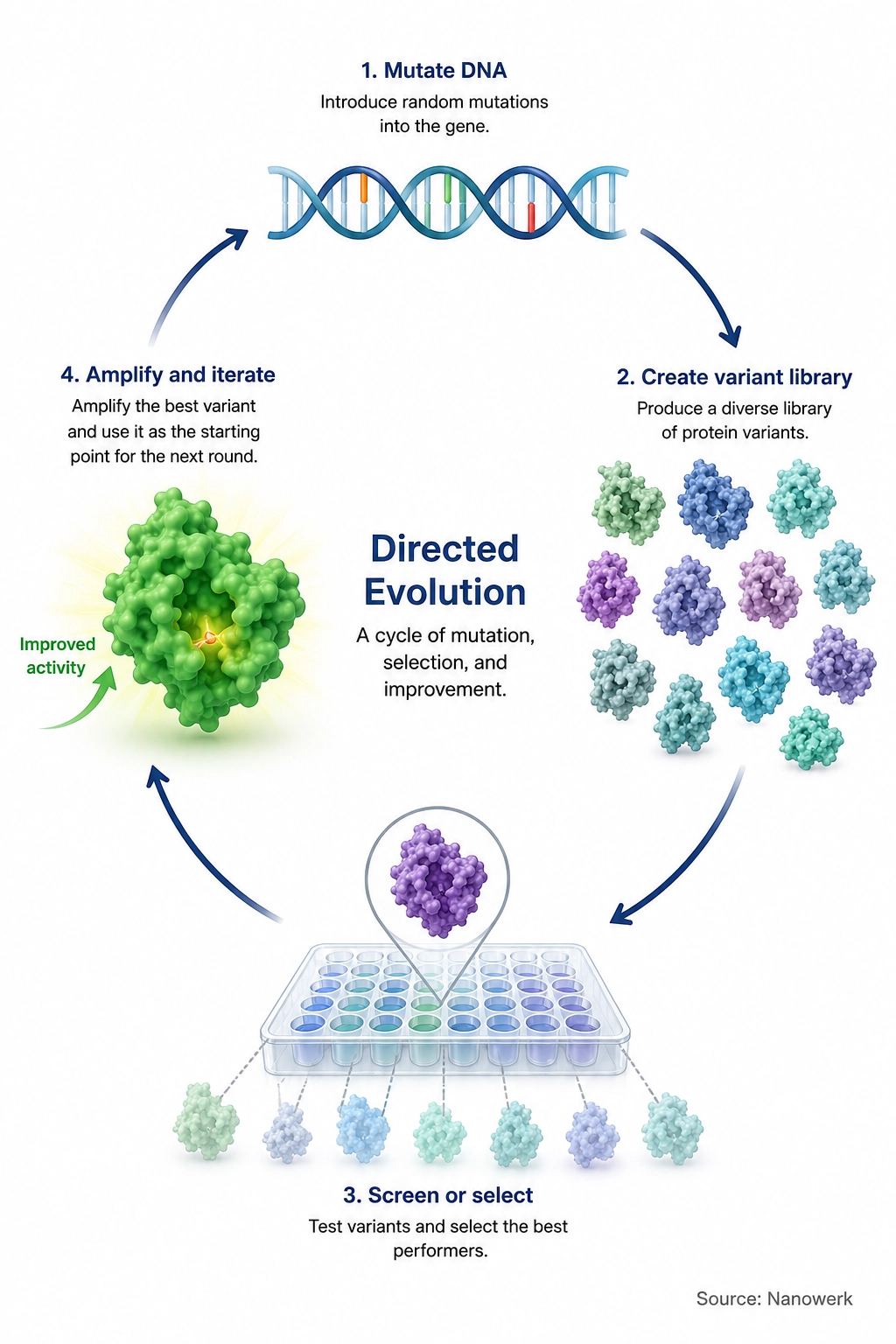
How Does Directed Evolution Work?
Every directed evolution experiment alternates between two operations. The first is diversification: a population of variant genes is generated from one or a few parent sequences, usually by introducing random mutations or by recombining related sequences. The second is screening or selection: the variant proteins are tested, and only those that improve the property of interest are kept. Crucially, a successful system must preserve genotype-phenotype linkage: the tested molecule's performance must remain connected to the DNA or RNA sequence that produced it, so that the genetic information behind a successful variant can be recovered and amplified.
Screening vs selection in directed evolution: in a screen, each variant is measured and ranked; in a selection, only variants that meet a threshold survive or are recovered. Screens can provide richer quantitative information, while selections can handle much larger libraries when the desired activity can be tied to survival, binding or another recoverable signal.
A useful way to picture the process is the fitness landscape, a conceptual map in which every possible sequence is a point and its height represents how well it performs the desired function. A single round of mutation explores the local neighborhood of the parent; selection moves the population uphill toward better-performing sequences. Repeating the cycle lets the population climb a peak step by step, accumulating beneficial mutations that would be vanishingly unlikely to appear all at once. This follows the core logic of Darwinian evolution, compressed into days or weeks and aimed at a goal chosen by the experimenter rather than by the environment.
The single most important practical rule of the field is often summarized as "you get what you screen for." Because only the property actually measured is optimized, a poorly chosen assay reliably produces variants that excel at the assay while failing at the real objective. Designing a screen or selection that genuinely reports the property of interest, and that can be applied to very large numbers of variants, is usually harder and more decisive than generating the diversity itself.
The Directed Evolution Toolkit
Diversity is generated with a small set of well-established techniques. Error-prone polymerase chain reaction copies a gene under conditions that introduce random point mutations across its length. DNA shuffling and related recombination methods fragment and reassemble a family of related genes, mixing beneficial mutations from different parents in a single step. Site-saturation mutagenesis takes the opposite, focused approach, replacing one or a few chosen positions with all twenty amino acids to exhaustively sample the most promising regions of a protein. The choice among broad random mutagenesis and focused libraries depends on how much is already known about the molecule's structure and active site.
Linking each variant protein to its encoding DNA is achieved through display and selection technologies. In phage display, each variant is fused to a coat protein of a bacteriophage so that the protein is presented on the virus surface while its gene sits inside the same particle; binders are then physically fished out of a vast library. Yeast and bacterial display present variants on the surface of living cells, which can be sorted at high speed by flow cytometry. Cell-free formats such as ribosome display and mRNA display keep each protein tethered to its own messenger RNA entirely in vitro, allowing libraries far larger than any cell population can hold. George Smith invented phage display in 1985, and Gregory Winter adapted it to evolve human antibodies.
When a property cannot be tied to survival or binding, high-throughput screening is used instead: variants are expressed in microplate wells or sorted droplets and assayed individually, often with a fluorescent or colorimetric readout. The same evolutionary principle is also applied to nucleic acids through SELEX, a method that iteratively enriches short DNA or RNA molecules, called aptamers, that fold into shapes binding a chosen target. In many cell-based formats, variants are carried on a plasmid and produced using standard recombinant DNA methods; cell-free display systems preserve the genotype-phenotype link without relying on living cells.
Directed Evolution Versus Rational and Computational Design
Directed evolution is one of three broad strategies for tailoring proteins, and in practice the three are increasingly combined. Rational design starts from a known structure or mechanism and introduces specific, hypothesis-driven mutations; it is precise and economical when the structure-function relationship is well understood, but it fails when that understanding is incomplete. Computational and de novo design uses physical models and, more recently, deep learning systems related to AlphaFold to predict sequences for a desired structure or function before any experiment is performed. Directed evolution makes the fewest assumptions of the three: it does not require a structure, a mechanism or a predictive model, only a way to generate diversity and a way to score it.
| Approach | Knowledge required | Main strength | Main limitation |
|---|---|---|---|
| Directed evolution | A diversification method and a screen or selection | Finds non-obvious solutions without a structural model | Limited by screening throughput and library size |
| Rational design | Detailed structure and mechanism | Precise, few variants to test | Fails where structure-function understanding is incomplete |
| Computational / de novo design | Predictive physical or machine-learning models | Can propose sequences before any experiment | Predictions still need experimental validation |
| Semi-rational / ML-guided | Partial structural data plus variant-activity data | Smaller, smarter libraries; faster convergence | Needs informative training data to be effective |
The non-obvious point in this comparison is that the methods are complementary rather than competing. Computational design is excellent at proposing a promising starting point but rarely delivers a finished, optimized molecule; directed evolution excels at the final refinement but wastes effort if it starts from a poor parent. The fastest modern campaigns use design or machine learning to choose where to focus mutations, then use evolution to optimize within that focused space, an approach often called semi-rational or machine-learning-guided directed evolution.
Applications in Industry and Medicine
Industrial biocatalysis is the area where directed evolution has had the broadest impact. Evolved enzymes are used in laundry and dishwashing detergents, in the processing of starch and textiles, and in the conversion of plant biomass to fuels, where natural enzymes are typically too slow, too unstable or too sensitive to process conditions to be useful as supplied by nature. A widely cited pharmaceutical example is the manufacture of the diabetes drug sitagliptin, where an evolved transaminase replaced a metal-catalyzed step and improved yield, purity and waste profile, illustrating why directed evolution is central to green chemistry and modern bioprocessing.
In medicine, display-based directed evolution transformed the discovery of protein therapeutics. Phage and related display methods are used to evolve monoclonal antibodies with high affinity and specificity for disease targets, and the approach yielded the first fully human antibody drugs. The same toolkit is used to engineer therapeutic enzymes, scaffolds and binding proteins, and to mature them for stability and reduced immunogenicity. These products are manufactured as recombinant proteins and constitute a large fraction of modern biopharmaceuticals.
A striking research frontier is the creation of enzymes that catalyze reactions with no natural counterpart. By evolving heme proteins, researchers have produced biological catalysts for carbon-silicon and carbon-boron bond formation and other transformations previously restricted to synthetic chemistry. This new-to-nature chemistry expands what living systems and engineered cells can make, and it links directed evolution directly to synthetic biology and to broader goals in genetic engineering.
Continuous and Machine-Learning-Guided Evolution
Conventional directed evolution is bounded by its slowest step: a human-operated cycle of mutation, expression and screening that takes days to weeks per round. Continuous evolution removes the human from the loop. In phage-assisted continuous evolution, the activity of the target molecule is wired to the reproduction of a bacteriophage growing in a flow of Escherichia coli, so that mutation, selection and replication occur autonomously and many rounds can be completed in a single day. Such systems make accessible optimization problems that would be impractical by hand.
Machine learning addresses the other bottleneck, the cost of screening. By training models on the measured activities of tested variants, researchers can predict which untested sequences are most likely to be improved and concentrate experimental effort on those, navigating rugged fitness landscapes with epistatic interactions far more efficiently than random sampling allows. This data-driven strategy, which connects directed evolution to bioinformatics and to protein synthesis at scale, is one of the most active directions in current molecular biology.
Limitations and Challenges
Directed evolution is powerful but not unconstrained. The library that can actually be tested is always tiny compared with the number of possible sequences. A protein of only 100 amino acids has 20100 possible sequences, so any campaign samples an infinitesimal fraction of sequence space and can become trapped on a local optimum that is good but not best. The screen or selection determines the outcome entirely, so a flawed assay produces flawed molecules. Building a high-quality, high-throughput selection is often the rate-limiting intellectual task, and properties that are hard to couple to survival or signal, such as expression level combined with activity and stability at once, are difficult to optimize together. These constraints are precisely why hybrid strategies that combine evolution with structural insight and machine learning have become standard.
Frequently Asked Questions
Who won the Nobel Prize for directed evolution? The 2018 Nobel Prize in Chemistry recognized laboratory evolution. One half went to Frances H. Arnold for the directed evolution of enzymes, and the other half was shared by George P. Smith and Sir Gregory P. Winter for the phage display of peptides and antibodies. The award marked the point at which evolution in a test tube became an accepted mainstream tool of chemistry and biotechnology.
Is directed evolution the same as genetic engineering? No. Genetic engineering is the deliberate, designed alteration of a known DNA sequence, whereas directed evolution makes large numbers of mostly random changes and then lets a screen or selection decide which variants survive. Directed evolution uses the molecular tools of genetic engineering, such as cloning and mutagenesis, but its defining feature is iterative selection rather than rational design of a specific sequence.
Can directed evolution be used on DNA and RNA, not just proteins? Yes. The same principle of iterated diversification and selection is applied to nucleic acids through a method called SELEX, which evolves short DNA or RNA molecules called aptamers that bind a chosen target with high affinity. Functional RNA molecules such as ribozymes have also been evolved in the laboratory, so directed evolution is not limited to proteins.
What is the difference between directed evolution and natural selection? Both rely on heritable variation and differential survival, but the selection pressure is different. In nature, the property that is optimized is reproductive success in a given environment, and no one chooses the outcome. In directed evolution, the experimenter defines the property to optimize and builds an artificial screen or selection that rewards it, so the process is goal-directed and typically far faster than natural evolution.
What was the first therapeutic antibody developed using phage display? Adalimumab, marketed as Humira, is widely cited as the first fully human therapeutic antibody developed using phage display to reach the market. Its commercial success helped establish display-based directed evolution as a mainstream route to antibody drugs, and many later antibody therapeutics have been discovered or optimized with related display methods.
Is directed evolution the same as adaptive laboratory evolution? Not exactly. Directed evolution usually refers to evolving genes, proteins, enzymes, antibodies or nucleic acids for a defined molecular property. Adaptive laboratory evolution evolves whole organisms or cell populations under controlled environmental pressure.
Further Reading
Nature Reviews Genetics, Methods for the Directed Evolution of Proteins
Angewandte Chemie International Edition, Directed Evolution: Bringing New Chemistry to Life
Nature Communications, Active Learning-Assisted Directed Evolution
