| Feb 27, 2023 |
Unlocking the full potential of perovskite solar cell technology with Machine Learning |
| (Nanowerk Spotlight) The development of new materials has played a significant role in the progress of humanity, both historically and presently. The study of materials is essential for developing new technologies, improving existing ones, and addressing societal challenges such as energy, environment, and healthcare. However, traditional methods for researching and creating innovative materials can be arduous and protracted, often necessitating extensive experimentation and testing. |
| Trial and error is a time-consuming and labor-intensive process that involves creating various combinations of materials and testing them until a suitable product is achieved. |
| Experimental testing, on the other hand, involves creating and testing numerous samples under different conditions, which can require a significant amount of laboratory equipment and materials. |
| The reliance on limited data can be a significant hindrance to the research process. Conventional methods for developing and studying new materials often rely on a small set of data, which can limit the potential for new discoveries and innovations. |
| In this context, certain methods of simulation and calculation, such as Density Functional Theory (DFT) and molecular dynamics, can to some extent assist in the development of new materials. However, there exist two significant limitations to these techniques: Firstly, they require significant computational resources and time, particularly as the complexity of the material increases, leading to an exponential increase in computational effort. Secondly, these methods are not well-suited for analyzing complex systems, such as perovskite solar cells, which are made up of several materials. |
The emergence of machine learning technology |
| Machine learning (ML) has simplified the process of material development by enabling the analysis of vast quantities of data. ML is a subset of artificial intelligence that allows computers to learn and make predictions based on data. ML has already been successfully used in various fields: |
|
|
| ML is now being applied to the study of materials, particularly complex systems. One of the key challenges in materials science is understanding the relationships between the structure, properties, and performance of materials. This challenge is particularly difficult for complex materials systems that involve multiple components, phases, and interactions. |
| This is where machine learning comes in. ML techniques provide a powerful approach for analyzing complex materials systems by automatically identifying patterns and relationships in large datasets. By analyzing data from experiments, simulations, or databases, machine learning algorithms can extract meaningful features and create models that can predict the properties or behavior of materials. |
Using Machine Learning for Innovation in Perovskite Solar Cells and Component Materials |
| There are many benefits to using ML, such as lower costs, the ability to predict the properties of unknown materials, and the ability to handle complex systems – making it a promising tool for material innovation. |
| For example, perovskite solar cells (PSCs) are complex devices made up of multiple materials that have many different factors affecting their properties, which makes it difficult to analyze them comprehensively. ML can efficiently handle these complexities and help scientists in the design of new PSCs. |
| Perovskite semiconductors have emerged as a promising candidate for next-generation solar cells due to their potential for high efficiency and low-cost production. |
| Perovskite solar cells have already demonstrated a high power conversion efficiency of over 25%, which is comparable to that of traditional silicon-based solar cells. Furthermore, PSCs can be fabricated using low-cost materials and processes, such as printing or solution processing, which can significantly reduce production costs. |
| However, perovskite solar cells are still a relatively new technology and there are challenges that need to be addressed before they can be commercially viable, such as their long-term stability and durability. Nevertheless, the potential benefits of perovskite semiconductors make them an exciting area of research in the field of photovoltaics. |
| The use of machine learning in perovskite solar cells and component materials (PSCCM) has skyrocketed over the past few years for two main reasons. First, there's been an enormous accumulation of data related to PSCCM, providing large eneough data sets for ML to make meaningful contributions. Second, an increasing number of scholars recognize the rapid development and immense potential of ML in high-throughput computing and complex multidimensional physicochemical spaces. |
| However, with so many different ML techniques and study subjects involved in different studies, researchers face significant challenges in studying this field. |
| To address this issue, a recent review in Advanced Functional Materials ("Machine Learning for Perovskite Solar Cells and Component Materials: Key Technologies and Prospects") outlines the current state and future prospects of ML in perovskite solar cell research, including data sources, feature extraction, algorithms, model validation, interpretation, and challenges. |
| The authors highlight and explain in detail the five different techniques that are essential for the development workflow of an ML model: |
|
|
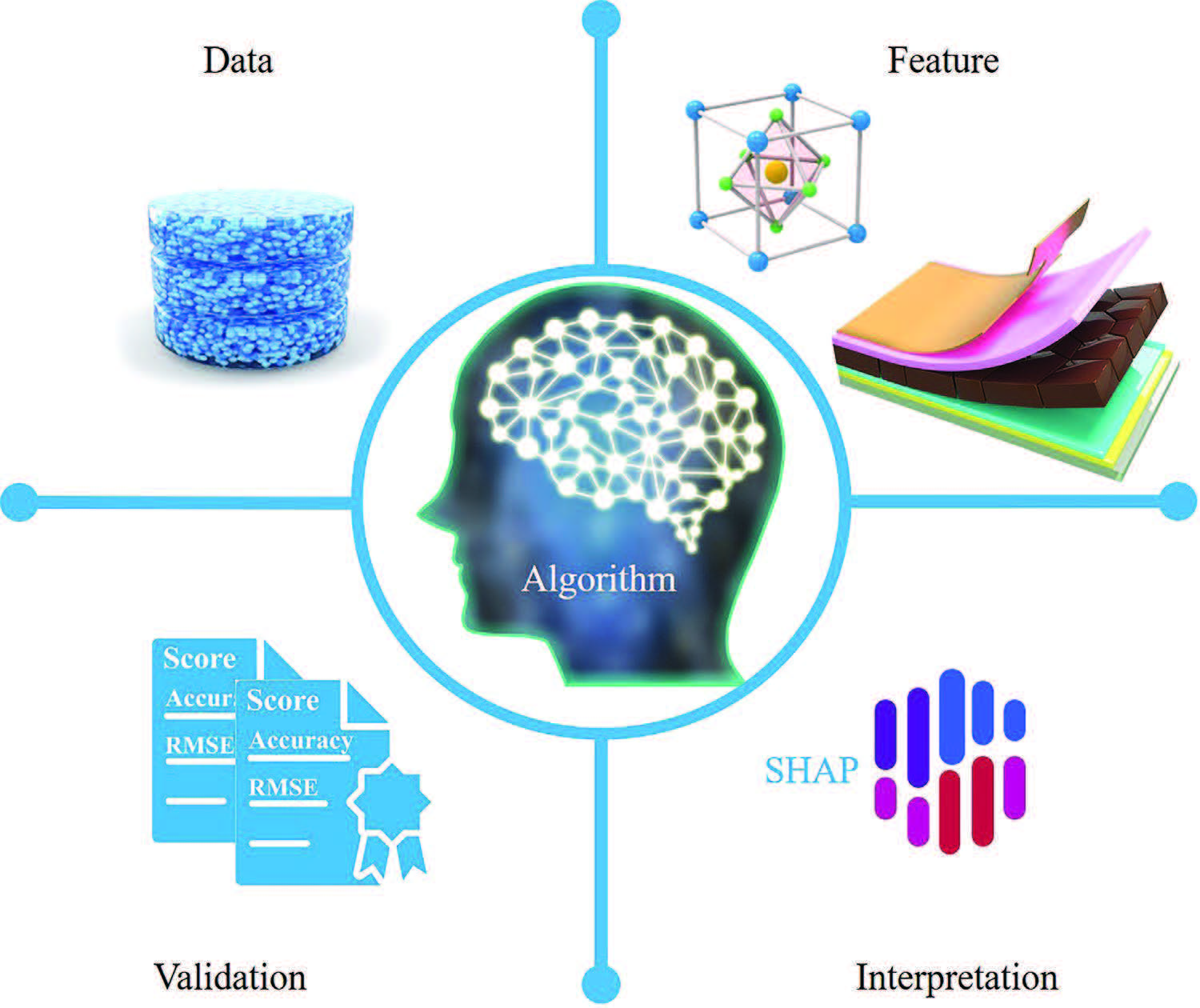 |
| Five types of technologies required to build ML models. (Reprinted with permission by Wiley-VCH Verlag) |
| Let's take a look at these five elements: |
The Data |
| The significance of data for ML models cannot be overstated, as it is even more crucial than the algorithm itself. The application context and generalization ability of ML models depend on a large amount of high-quality data, especially some deep learning algorithms. |
| Materials scientist produce and use various types of data – computational and experimental – to study materials used in perovskite solar cells. This includes tabular data containing chemical and physical properties of the materials, image data such as SEM and XRD, and text data such as the materials' names and cell preparation methods. These data are utilized as the input (descriptors, features, independent variables) and output (labels, target variables) of the ML models. |
| An open-access database and analysis tool for perovskite solar cells based on the FAIR data principles (findability, accessibility, interoperability and reusability) contains data from over 42,400 photovoltaic devices with up to 100 parameters per device, categorized into Reference data, Cell definition, Device stack, Synthesis, and Key metrics. |
 |
| Categories of data in the perovskite database. (Reprinted with permission from Nat Energy 7, 107???115 (2022)) (click on image to enlarge) |
| This database also includes interactive tools for data exploration, analysis, filtering and visualization, which are freely available at The Perovskite Database Project. |
The Features |
| To predict the properties of perovskite solar cells, there are key factors that must be considered, called features or descriptors. These factors are used to simplify and generalize the model and help interpret its effectiveness. To achieve this, the raw data must be refined and reduced in dimensionality through a process called feature extraction and molecular descriptor transformation. |
| However, the complexity of the target attributes and their logical connections can make feature extraction difficult. This has led to the emergence of several feature selection methods, including the filter method, wrapper method, and embedded method. The filter method scores each feature based on statistical methods before the model is trained, without being combined with the model. |
| PSCs also contain components such as transport layer materials and passivation materials made of polymers and organic small molecules. Transform the properties of these materials into digital features is necessary – and a hot research direction in the field of computational materials – so that they can be used in ML algorithms. These digital features are called molecular descriptors, which come in two types: quantitative and qualitative. |
| Quantitative descriptors refer to the microscopic physicochemical properties of a molecule, while qualitative descriptors, also known as molecular fingerprints, are digital representations of a molecule's chemical structure. Molecular fingerprinting is the most commonly used technique for transforming molecular descriptors into digital features for use in machine learning models. This technique preserves the molecule's structural and physicochemical information, allowing it to be used as input to predict the properties of organic materials for PSCs. |
The Algorithm |
| Machine learning is a type of computer programming that uses math and statistics to help computers learn from data. There are different types of machine learning methods that are used for different problems. Some methods are based on the type of problem, like classification, regression, clustering, and dimensionality reduction. Other methods are based on whether the data has labels or not. |
| Supervised algorithms are used for classification and regression problems, which involve predicting a label for each data point. Unsupervised algorithms are used for clustering and dimensionality reduction problems, which involve finding patterns in the data without any labels. |
| Some machine learning algorithms can work with both classification and regression problems. The main difference between these two problems is whether the labels are discrete or continuous variables. Clustering problems do not have labels, so the algorithm can only group data points based on their similarity in the data space. |
| The selection of an appropriate algorithm typically depends on several factors, including the reliability of the model, the format of the data (e.g., tables, images, text), and the amount of data available. In the realm of PSCCM, a significant portion of the data is typically in tabular form. |
| The authors classify common ML algorithms into three main categories: Classical Learning, Ensemble Learning, and Deep Learning (DL). Discussing each method, they conclude that, since there are usually no obvious space or time links between features, and the sample volume of the data is small and heterogeneous, ensemble learning algorithms with trees typically outperform DL. |
Model Validation and Optimization |
| Machine learning is a powerful tool used to predict unknown data using models trained on known data. To ensure the accuracy and reliability of these models, proper validation methods and optimization techniques are necessary. However, there is often confusion surrounding these techniques, such as using scores from training or validation sets to judge a model's performance. It's important to understand two key concepts: model parameters and hyperparameters, and the role of training, validation, and test sets. |
| Model parameters are variables within the model that can be automatically adjusted based on training data, while hyperparameters are external variables that must be set manually. The training set is used to adjust model parameters, the validation set is used to optimize hyperparameters, and the test set is used to evaluate the model's generalization capability. It's crucial to note that the test set must be completely separate from the training and validation sets to ensure objective evaluation. |
| While the test set is used to evaluate the final optimized model, it cannot replace the validation set for hyperparameter search. If the test set is used for optimization, it can lead to overfitting and compromise the model's ability to generalize. |
| The two most popular methods for model validation and optimization are Holdout and k-fold Cross-validation and the authors discuss them in great detail in their review. |
Model Interpretation |
| In the field of artificial intelligence, one of the most cutting-edge research directions is developing methods to interpret the decisions made by machine learning (ML) models. The interpretation of models is crucial to understanding why a model makes certain decisions. By interpreting these decisions, researchers gain insights into the data and the model's behavior, which can help them improve the model's accuracy and reliability. |
| For the purpose of their review, the authors discuss interpretable algorithmic models (which include generalized linear model, decision tree, and symbolic regression) and the external explanation of the black-box model. |
| After introducing and discussing the ML techniques, tools and resource libraries that may be used in the PSCCM field, the review turns to the applications of ML in the PSCCM field. |
| In order to enable researchers to quickly obtain the required ML technologies and entry points in the field of PSCCM, the authors propose a complete technical deconstruction method for the ML technologies. |
| The 67 papers that they have focused on for their review, with detailed ML technical descriptions and representation, are deconstructed with regard to 10 aspects of ML application: 1) Date (publication time of the article). 2) Data and code condition 3) Object (Perovskite solar cells or Perovskite materials, according to the source of the label). 4) Issues (Properties of the problem that the algorithm solves). 5) Input (The input data condition of the optimal model, including the number and type of inputs). 6) ML algorithms (ML algorithms used in the study). 7) Label (Label properties used for model training). 8) Performance (Model performance under optimal algorithm). 9) Explanation method (The used explanation method of the ML model and features). 10) ML Purpose (Application and meaning of ML model). |
| The deconstructed ML techniques, with corresponding descriptions, methods and sources, are presented in tabular form. The authors then go on to detail several papers with complete research steps and great importance for the applications of ML in the PSCCM field. |
| Looking towards the future, they highlight and discuss a number of urgent challenges that affect the further development of ML in PSCCM: the barrenness of data, the choice of model inputs, the practicality and credibility of the model, and the rationality of the study steps. |
 By
Michael
Berger
– Michael is author of four books by the Royal Society of Chemistry:
Nano-Society: Pushing the Boundaries of Technology (2009),
Nanotechnology: The Future is Tiny (2016),
Nanoengineering: The Skills and Tools Making Technology Invisible (2019), and
Waste not! How Nanotechnologies Can Increase Efficiencies Throughout Society (2025)
Copyright ©
Nanowerk LLC
By
Michael
Berger
– Michael is author of four books by the Royal Society of Chemistry:
Nano-Society: Pushing the Boundaries of Technology (2009),
Nanotechnology: The Future is Tiny (2016),
Nanoengineering: The Skills and Tools Making Technology Invisible (2019), and
Waste not! How Nanotechnologies Can Increase Efficiencies Throughout Society (2025)
Copyright ©
Nanowerk LLC
|

Become a Spotlight guest author! Join our large and growing group of guest contributors. Have you just published a scientific paper or have other exciting developments to share with the nanotechnology community? Here is how to publish on nanowerk.com. |
